导读大家好,我是小兰,三晋生活网的编辑。以上就是我给大家的答案。互联网档案馆的一项新计划,通过链接到被引用书籍的数字预览,可以更容易地
大家好,我是小兰,三晋生活网的编辑。以上就是我给大家的答案。
互联网档案馆的一项新计划,通过链接到被引用书籍的数字预览,可以更容易地检查维基百科中的引文。当一本书的扫描版可用时,它应该让源更容易说出维基百科文章所声称的内容。
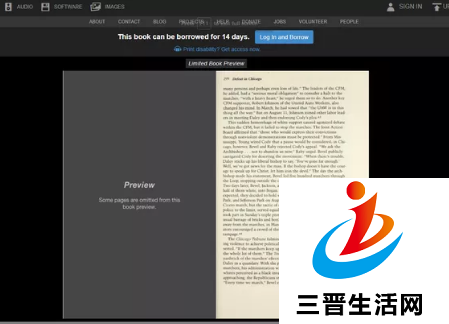
尽管总是可以通过追踪引用的任何书籍的实际副本来完成同样的操作,但对于在紧迫的截止日期工作的记者或学生来说,这尤其不切实际,尤其是对于难以找到的书籍。理论上,新计划意味着你只需一次点击就能获得来源。但事实上,将数百万维基百科参考文献与相关书籍进行匹配需要一些时间。到目前为止,互联网档案馆已经将相对少量的13万次引用链接到了5万本书上。这些计划还依赖于维基百科的作者以正确的格式引用书籍,他们需要为系统正常工作指定准确的页码。根据Wired的报告,ISBN号对于查找匹配非常有帮助,但并不是每本书都有。
除了将引文与正确的图书进行匹配的挑战之外,互联网档案馆在图书数字化方面也取得了良好的进展。《连线》报道,该机构拥有380万册扫描图书的数据库,日扫描速度超过1000。互联网档案馆表示,希望在未来几年再增加400万册图书。
将维基百科的图书引文数字化只是互联网档案馆试图让准确信息更容易在网上找到的一部分。除了图书参考资料方面的工作,它还一直在抓紧维基百科,用其回看机器中存档页面的链接替换损坏的参考资料。截至10月初,其互联网归档机器人已经修复了维基百科上近600万条受损引文。
更正:互联网存档的日存档速度是1000,而不是原来的10000。澄清补充说,该组织将在未来几年内再让400万本书上线,而不是总共400万本书。
本文就为大家讲解到这里了。